
Haojie Huang, Ziyi Yang, Robert Platt*
Table of Contents
3D Shape Completion
3D shape completion from partial point clouds is a fundamental problem in computer vision and computer graphics. Recent approaches can be characterized as either data-driven or learning-based. Data-driven approaches rely on a shape model whose parameters are optimized to fit the observations. Learning-based approaches, in contrast, avoid the expensive optimization step and instead directly predict the complete shape from the incomplete observations using deep neural networks. [Stutz et al.]

Related Works
PointNet is a pioneer in using the MLP-based approach to learn point clouds. It combines pointwise multi-layer perceptrons with a max-pooling aggregation function to achieve invariance to permutation and robustness to perturbation. After PointNet, FoldingNet proposed a folding-based decoder that deforms a 2D grid onto the 3D surface of a point cloud. Following previous works, PCN proposed the coarse-to-fine procedure to densify the point cloud.
However, these approaches just aggregated the global information from the whole point cloud without focusing on the local information of each point’s neighbors, neither did they take the various local properties of different points into account during the generation process. Compared with MLP-based approaches, graph-based methods could extract local information of each point. Most recent graph-based convolution methods operate on groups of spatially close neighbors. ECC is the first one to apply graph convolutions to point cloud classification. After that, DGCNN proposed a more generalized edge convolution method with dynamic graph updates to encode the local neighborhood information for point clouds. Inspired by DGCNN, DCG introduced this method to point cloud completion following a coarse-to-fine fashion. However, the edge convolution is computation expensive in large graphs. After Graph Attention Network, GAC inherited its ideas to apply attention mechanism to the point cloud segmentation area.
To the best of our knowledge, we are the first to directly combine the graph-level local information with the global structure information in the encoder and utilize surface normals to incorporate pointwise local properties for shape completion.
Model
General Structure
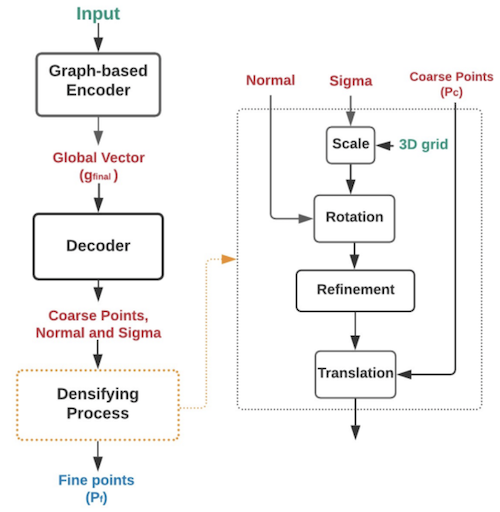
The architecture of GASCN. It has a graph-based encoder that integrates each point’s local information with the point cloud’s global structure information. The decoding process utilizes surface normals and coarse points to rotate and translate adaptive 3D grids to densify coarse point clouds.
Encoder Structure
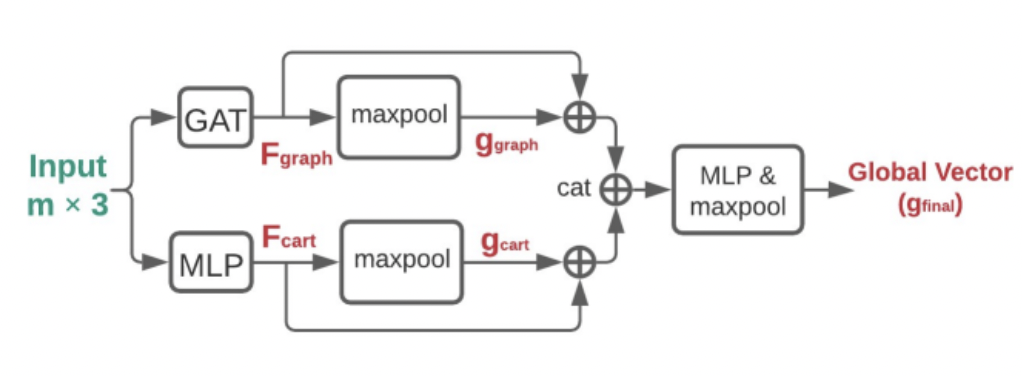
Graph-based Encoder of GASCN model. It encodes each node feature with its neighbors’ information by graph attention layer, its mapped Cartesian feature by point-wise MLP, and two types of global vectors, extracted from the max-pooling operation.
Decoder Structure
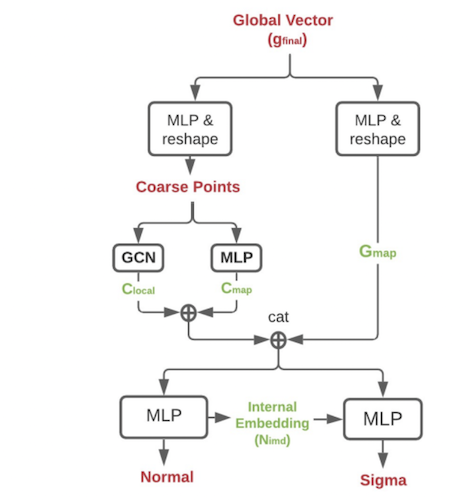
Decoder Architecture. The coarse points decoder consists of three fully connected layers. The normal decoder takes as inputs the mapped coarse point coordinate, its neighbors’ information, and the mapped global vector. The sigma decoder takes as inputs the normal internal embeddings, and then applies three pointwise MLP layers to output pointwise-attentive sigmas.
Experiments
Quantitative Result
 Point completion results comparison on ShapeNet using Chamfer Distance (CD) with L2 norm computed on 16,384 points and multiplied by 10^3. The best results are highlighted in bold.
Point completion results comparison on ShapeNet using Chamfer Distance (CD) with L2 norm computed on 16,384 points and multiplied by 10^3. The best results are highlighted in bold.
Qualitative Result
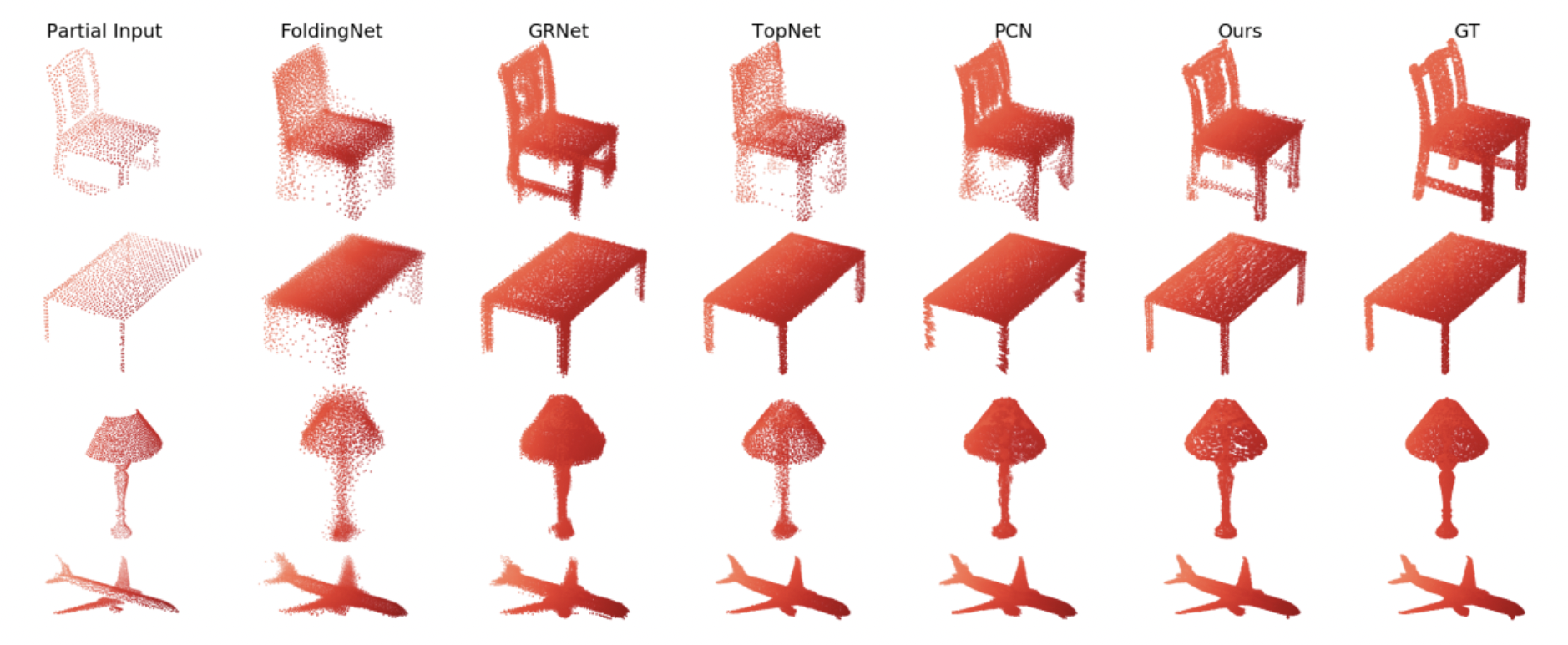 Visual Results Comparison. A partial point cloud is given and our method generates better complete point clouds.
Visual Results Comparison. A partial point cloud is given and our method generates better complete point clouds.
More Information
UPDATE 10/03/2021: This paper has been accepted by 3DV, 2021. The complete version of our paper is available at here.