
Table of Contents
Introduction
RL in Language Generation

Reinforcement Learning (RL) in language generation has been investigated for a long time, particularly because it’s supposed to be a solution for exposure bias and different learning targets during training and testing (train with MLE, test with BLEU). Policy gradient methods have been implemented widely, while the efficiency of RL is always questioned. In general, RL method suffers from high-dimensional discrete action space, reward sparsity, and easy to be trapped in local minimum.
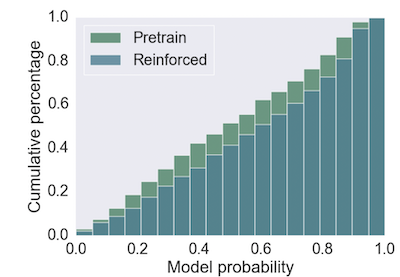
Due to above reasons, RL in language generation has been controversial. ‘On the Weaknesses of Reinforcement Learning for Neural Machine Translation’ (Choshen et al) and ‘Revisiting the Weaknesses of Reinforcement Learning for Neural Machine Translation’ (Kiegeland et al) are two interesting papers to read. Chosen et al argued that RL just modified the probability distribution to be more ‘peaked’. The most astonishing point they found is that the improvement over the pretrained model appears even when they replaced the reward function (BLEU score, in their case) by a constant reward. Following Choshen et al, Kiegeland et al conducted further experiments and showed empirically that empirical improvements over a strong pretrained model vanish when there is little to learn from the new feedback, which means the reason of no obvious improvement is observed from Choshen et al’s experiment is that minimizing MLE and maximizing BLEU score are optimizations at same objective.
GAN in Language Generation
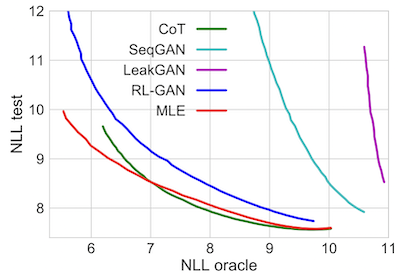
Generative Adversarial Model (GAN) for language generation as well been studied broadly. The biggest challenge in implementing GAN in language generation model is that the output of the generator (language generation model) is manually ‘picked’ at each timestep of the decoding phase. In other words, we pick the token according to the probability distribution of the generation model’s output instead of using the probability itself as the result, which prevent us from backpropagating the GAN loss through the generator (in this sense, GAN loss is similar to BLEU for they’re both non-differential). seqGAN by Yu et al introduced REINFORCE with Monte-Carlo roll-out for backpropagating, and there are also non-RL GANs like CoT and FM-GAN. However, at the time of 2019, a famous paper, ‘Language GANs Falling Short’ by Caccia et al, came out. It pointed out that GAN model in language generation is flawed by proving MLE models can outperform all existing GAN models when both quality and diversity are taking into account (‘Temperature Sweep’). After that, language GANs became less popular.
Language Generation in Vision-Language Generation
Language generation model in vision-language generation is first introduced by Fried et al in the Speaker-Follower model. Following Speaker-Follower, Tan et al proposed EnvDrop model, which improve the generation model by stacking multiple LSTM networks. It has been empirically showed that generation models can substantially improve the ‘Speaker’ (grounding model) by augmenting instruction-trajectory pairs and then deploying curriculum training on the augmented dataset.
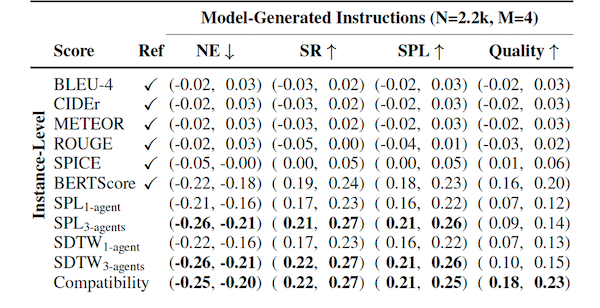
However, instructions generated by the language generation model are usually hard to evaluate, especially when the training objective is hard to express in a mathematical form like in our case, where the ultimate goal is to make generated instructions understandable to human. In this sense, Zhao et al evaluated different metrics on the topic of evaluating generated instructions. An important finding is traditional language metric such as BLEU, METEOR, and CIDEr are inefficient on evaluating the quality of generated instructions, while SPICE is efficient on system-level evaluation, and BERTScore is efficient on evaluating model-generated instructions, and using VLN agents as evaluation model will carry out promising result on evaluating all instructions. What’s more, they also proposed a compatibility neural network for evaluating instructions on all purposes.
Proposed Method
Starting with the pretrained generator, we uses the REINFORCE to backpropagate non-differentiable learning target to the model. The reward function is consisting of two parts: BERTScore and VLN agents. The second reward (Agent) explores the idea of training a generator directly to produce better instructions. We use a pretrained grounding model to take actions in the simulator according to the generated instructions, and return reward signal equal to the distance between the goal location and the agent’s final location.
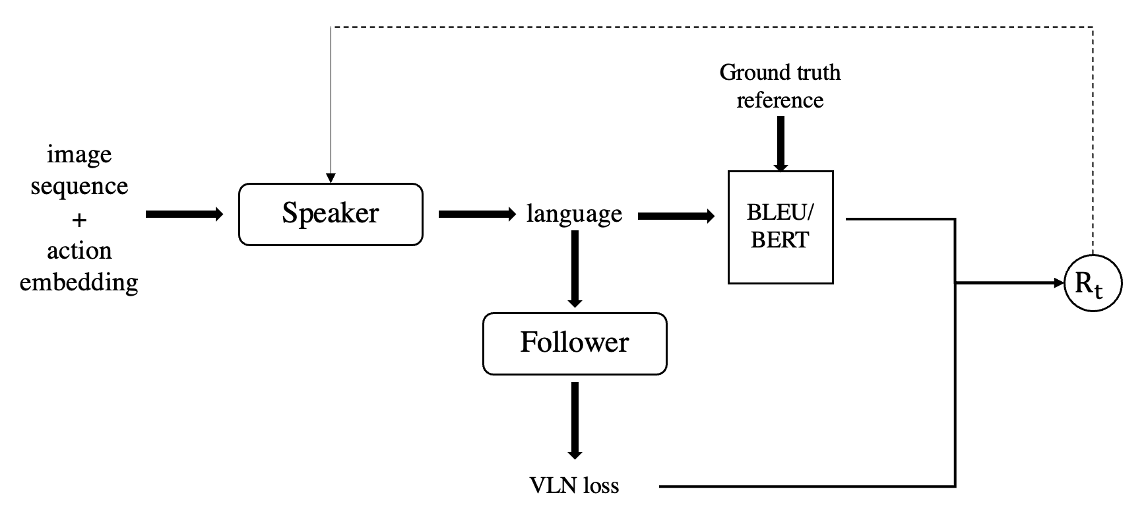
At the same time, we can introduce the compatibility model into the loop. Before introducing it, there are several ways we can improve it. First, the viewpoint swapping and random walk method in hard negatives mining could be improved by filtering candidate using normalized dynamic time warping. Second, the bi-directional LSTM for language encoding could be easily replaced by more advanced structures, such as transformers and pretrained BERT model.
There are multiple ways of implementing the compatibility model; the first one is to use it as a scorer to provide reward to the generation model, and the second one is to use it as a discriminator and combine it with the generation model (as a generator) to be a GAN model and update both of them simultaneously. Obviously, the second way is much harder than the first one, since training a GAN model will need a lot more effort on balancing the strength of the generator and the discriminator. On the other side, if the GAN model works as expected, the performance of the generation model will be further enhanced and the compatibility model will also be in a better shape.
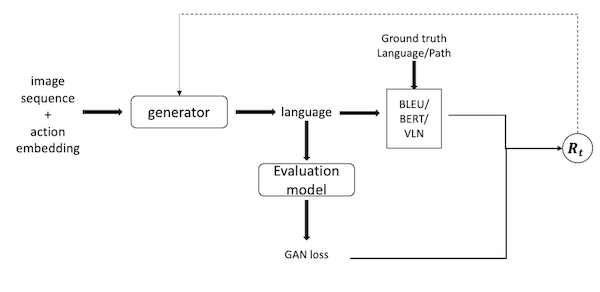
Practically speaking, to use the compatibility model as a scorer will be realized simply since it just introduces a new kind of reward into existing reward function, while to combine two models into a GAN model will create a new loop and thus hard to implement. However, as we discussed in the Introduction section, the non-differentiable loss could be successfully back-propagated by RL methods! In other words, if we still use REINFORCE for training, the only difference between these two ways will just be whether updating the compatibility model when training. In this sense, it’s pretty clear that we should try using it as a scorer first and then investigating GAN structure.
Progress
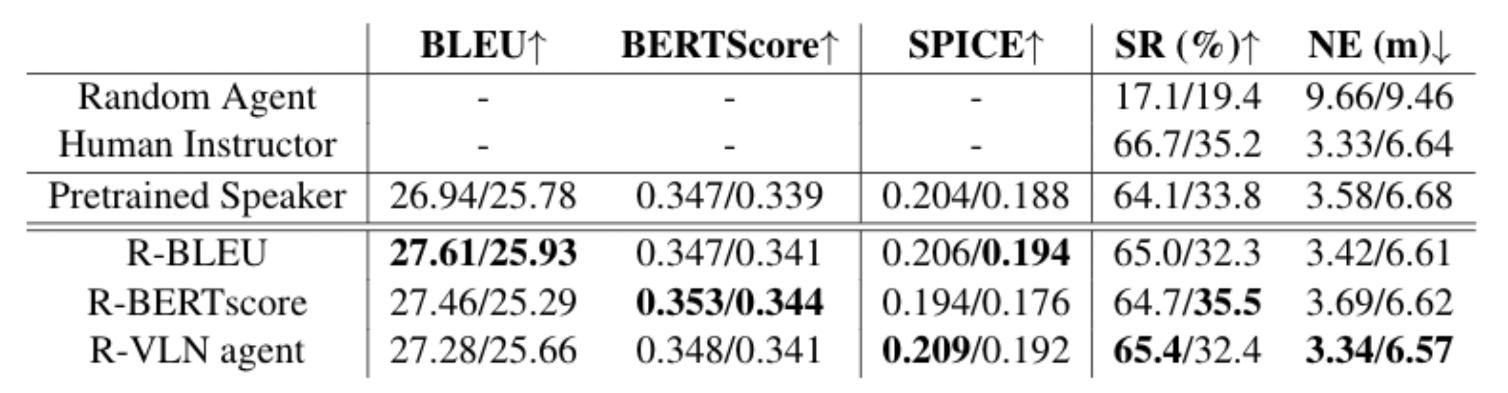
In the early attempts, I trained the pre-trained model with three different reward functions: BLEU, BERTScore and VLN agents. I’ve abandoned BLEU score after Zhao et al., while there are still some interesting findings in the result table. For example, the model trained with VLN agents is able to outperform human on validation_seen dataset! We can easily tell that this is because the generation model is exploiting VLN agents, but it can still serve as a counter-evidence against the ‘Weakness of RL in NMT’ paper, because we show empirically that ones can directed the model to desired direction by controlling the reward function.
Combining different reward functions is cool, but it will also be hard to evaluate. Inspired by ‘Language GANs falling Short’, I’m training multiple model with different hyperparameter combinations and plotting a ‘BERTScore-VLN agent sweep’ curve.
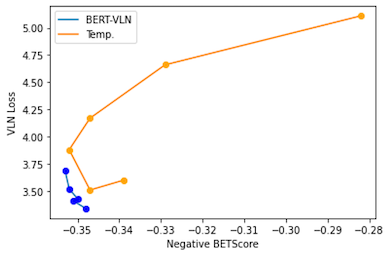
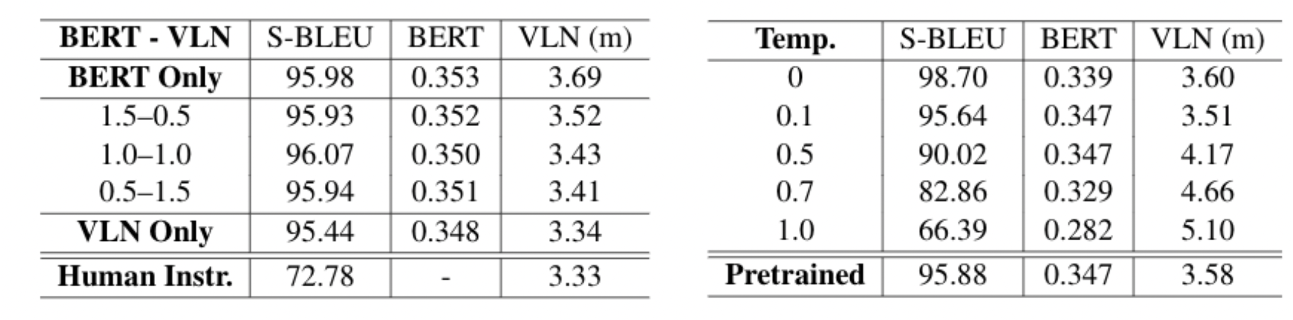
As shown in the table and the figure above, our model plots out a curve that is on the left-bottom of the temperature sweep curve, which indicates that RL training did improve the pre-trained model along the desired direction. Also, though the RL model has a slightly higher Self-BLEU score in comparison to the pretrained one, indicating the lower diversity, it could carry out higher BERTScore on the linguistic side and lower VLN loss on the navigation side, which are prioritized in VLN tasks. It supports the fact that changing temperature could only improve the diversity of the generated instruction, but the effect on other metrics is random, even on a linguistic metric like BLEU score. This also serves as another proof that RL methods are effective in optimizing language models with designed reward functions instead of just making the probability distribution peakier.
For reproducing the compatibility model from Zhao et al., I’ve spent a month on rebuild the hard negative dataset. I found it hard to rebuild the dataset because I have limited access to Google Cloud. I had to turn to some alternatives, while these alternatives result in smaller dataset and poorer quality (I doubt so).
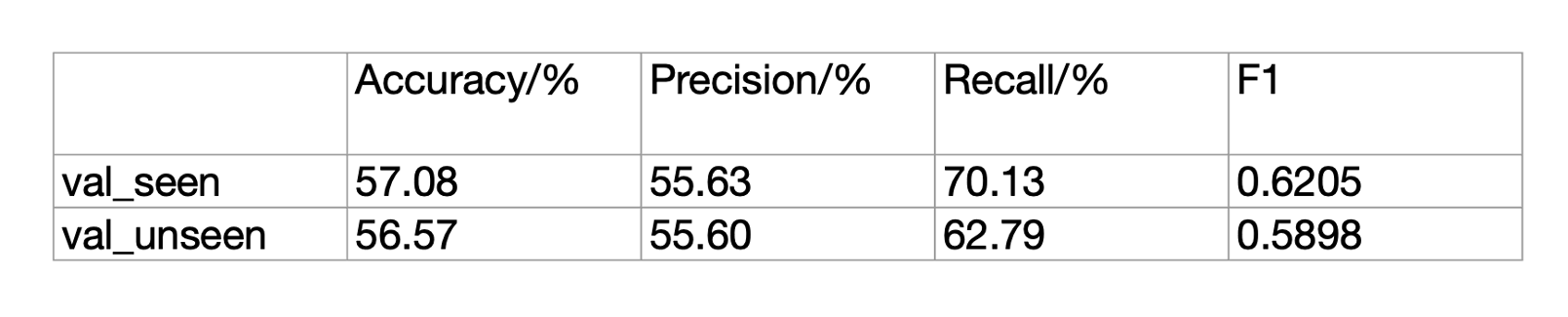 The reproduced compatibility model could achieve 56%~57% accuracy, but it does not match the performance reported by Zhao et al. (70%). Further experiment shows that REINFORCE could still improve the score output by the compatibility model, while it does not lead to improvement on any metrics we used (BLEU, BERTScore, and VLN loss). Here, we proposed two hypotheses for the reason: 1. The accuracy of the reproduced compatibility model is lower than the minimum requirement for being used as a scorer. 2. The improvement is not measurable by all three metrics that previously mentioned, and might need human evaluation for further analysis.
The reproduced compatibility model could achieve 56%~57% accuracy, but it does not match the performance reported by Zhao et al. (70%). Further experiment shows that REINFORCE could still improve the score output by the compatibility model, while it does not lead to improvement on any metrics we used (BLEU, BERTScore, and VLN loss). Here, we proposed two hypotheses for the reason: 1. The accuracy of the reproduced compatibility model is lower than the minimum requirement for being used as a scorer. 2. The improvement is not measurable by all three metrics that previously mentioned, and might need human evaluation for further analysis.
Till now, my current work formed my master’s thesis.
(UPDATED:11/29)