
Maxwell Love, Seth Pate, Wei Xu, Ziyi Yang, Lawson Wong*
Table of Contents
Rendezvous
Effective collaboration requires two-way communication. To enable the widespread adoption of collaborative robots, they need to be able to communicate effectively with non-expert human users. Natural language is an expressive and effective medium for communicating with humans, since it does not require additional training for the user. Natural language is already used in numerous robotics applications, including some ongoing projects within Prof. Lawson Wong’s group. However, most existing work focuses on one-way communication: from human to robot. In contrast, work on the reverse direction of robot-to-human communication is sparse. This research project involves an application that requires two-way communication via natural language.a

This project aims to build a system that allows an agent/robot to instruct a human user about how to navigate from their current location to an intended destination. This involves at least the following tasks: (a) Localize the human within a known environment map. This requires understanding a description given by the user in natural language, and if the location is ambiguous, requires follow-up questions from the robot to disambiguate the user’s location. (b) Plan a path for the human to follow. It is unclear whether the shortest path is necessarily optimal in this case. Since the path will need to be conveyed to the user, it may be more desirable to pick a path that is easily described and not confusing, even if it is slightly longer. (c) Describe the path to the human using natural language. This is another part of the project that requires natural language generation. Similar to the previous point, this requires reasoning about whether the instructions are easy to follow.[Wei Xu]
Dataset & Evaluation
Where possible, we use data and metrics from the VLN community. The R2R dataset cannot be used directly to train a locating agent, because it does not associate language to locations。 Instead, we started with Room-Across-Room (RxR), which is similiar but includes pose traces and times for each word. We split up each instruction, matching each phrase of words to its closest graph location, to make our language dataset.
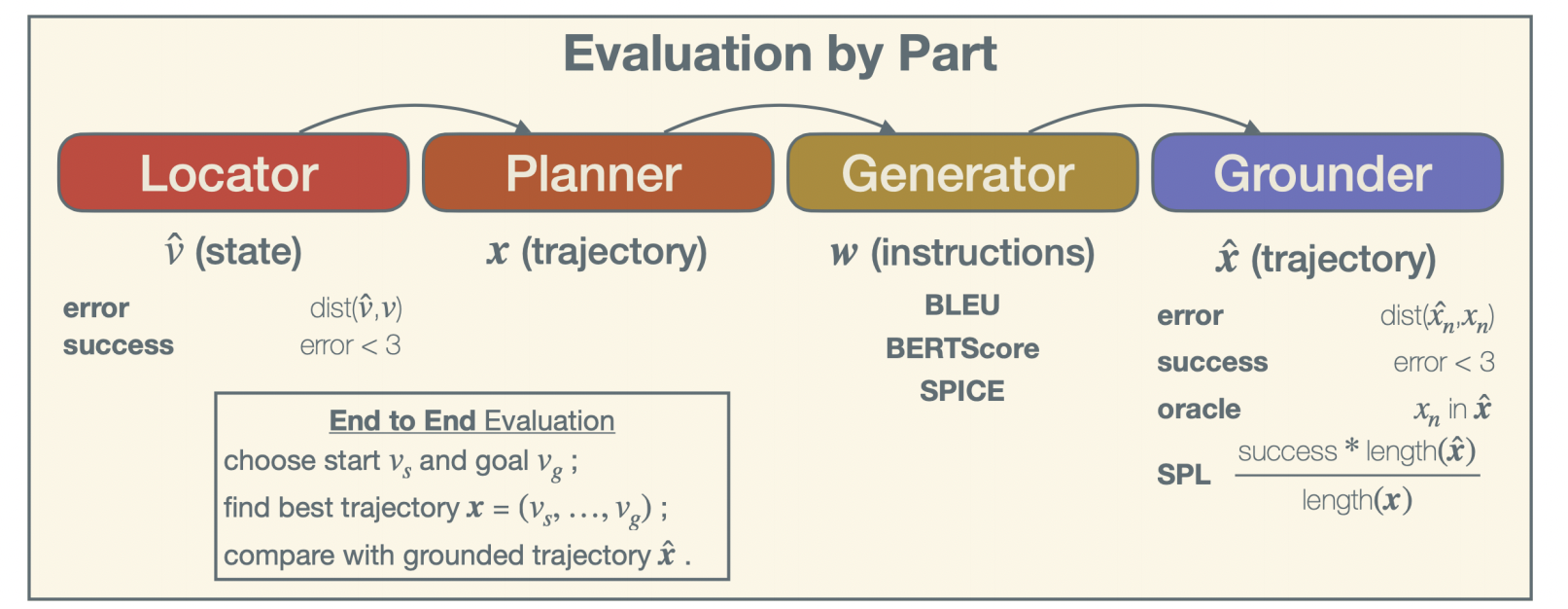
We suggest some simple means to evaluate an agent’s ability to give instructions.
Location Evaluation: We evaluate the locator on its error, the graph distance within the Matterport simulator between its viewpoint and the target viewpoint. We also report success rate; the task is a success if the error falls within a 3m threshold, a convention for this dataset.
Planning Evaluation: In the sparse graph of the Matterport environment, there tends to be one clearly best plan for any two points, so evaluating the planner made little sense here. In other environments, we could evaluate planned trajectories by length, elevation change, etc. We could also test ‘user-aware’ planners by giving them two arbitrary locations and running their resulting plan through a fixed generator and grounder. Different planners would elicit different performance from the generator and grounder, giving us a basis for comparison.
Generation Evaluation: Generators are usually evaluated by comparing their output to Reference translations using metrics like BLEU and BERTScore. These measures were not meant to evaluate instructions per se, and are often of limited value. Zhao et al. developed a neural network ‘compatibility model’ to assign instructions and trajectories a similarity score, which correlated well with human evaluation. We do not use their model here; instead, we evaluate our generator directly on how well the user grounds its instructions, producing grounded trajectory. As in location, we compare the final position of the grounded trajectory with the final position of the actual trajectory to find error. In addition to success rate, there is the more generous oracle success rate, measuring whether the agent ever encountered the goal. Finally, there is success weighted by path length, SPL, which penalizes agents for taking a longer path than necessary. We use a single pretrained grounding model, the Speaker-Follower model, as the fixed grounder. It is no longer state of the art, but is easily implemented, and good enough for a reasonable comparison of a generator. A better evaluation would include an ensemble of different grounding models, as well as a human evaluation on the simulator.
Baseline Results
We report empirical results on location and generation using some baseline models, highlighting the large performance gap between existing models and ideal.
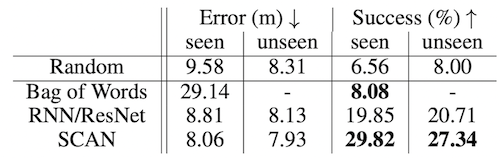
Localization
Bag of Words: Empirically estimates p(v_i|l) from word frequency in the training text, then greedily chooses from among all viewpoints. By design, cannot generalize to unseen viewpoints.
RNN/ResNet: Encodes image at a viewpoint with a ResNet trained on ImageNet, producing h_v. Encodes word embeddings with an LSTM to make a context vector h_w.Trains a deep neural network to produce y = f(h_v, h_w), choosing the highest y.
Stacked Cross Attention: SCAN uses attention to align parts of the viewpoint image p with individual words, giving an overall similarity score. Chooses the most similar viewpoint.
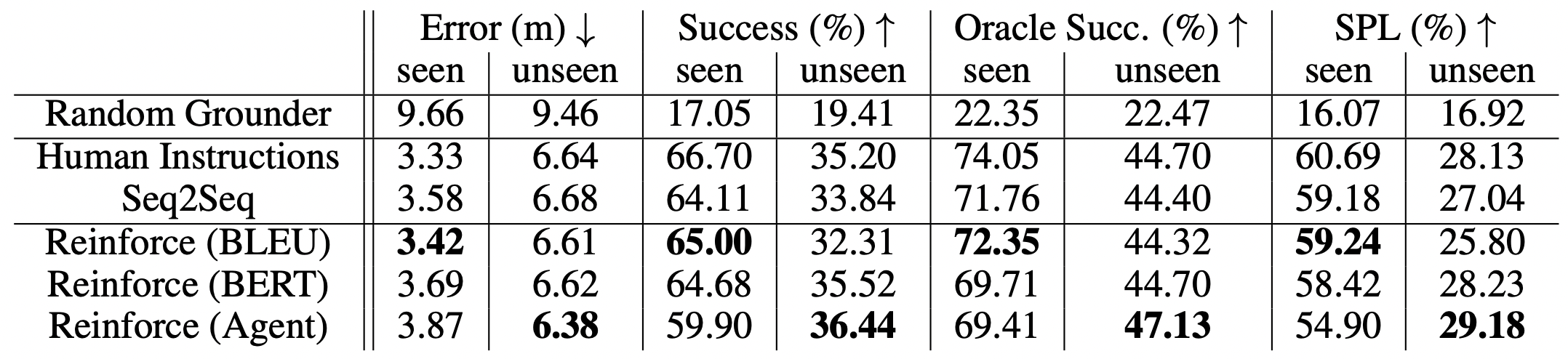
Generation
Sequence to Sequence: A seq2seq LSTM with attention. Minimizes cross-entropy loss of output tokens.
REINFORCE: Starting with the pretrained generator above, uses the REINFORCE method to backpropagate an undifferentiable learning target to the model. We test two reward functions based on the standard language metrics BLEU and BERTScore. A third reward (Agent) explores the idea of training a generator directly to produce better instructions. We use a pretrained grounding model to take actions in the simulator according to the generated instructions, and return reward signal equal to the distance between the goal location and the agent’s final location.
More information
This work has been submitted to AI-HRI (our AI-HRI submission). I’m continuing on the topic of improving the performance of the generator by RL, see my latest post for more details.
UPDATE 09/09/2021: This paper has been accepted by AAAI Fall Symposium on AI for HRI.