
Table of Contents
Introduction
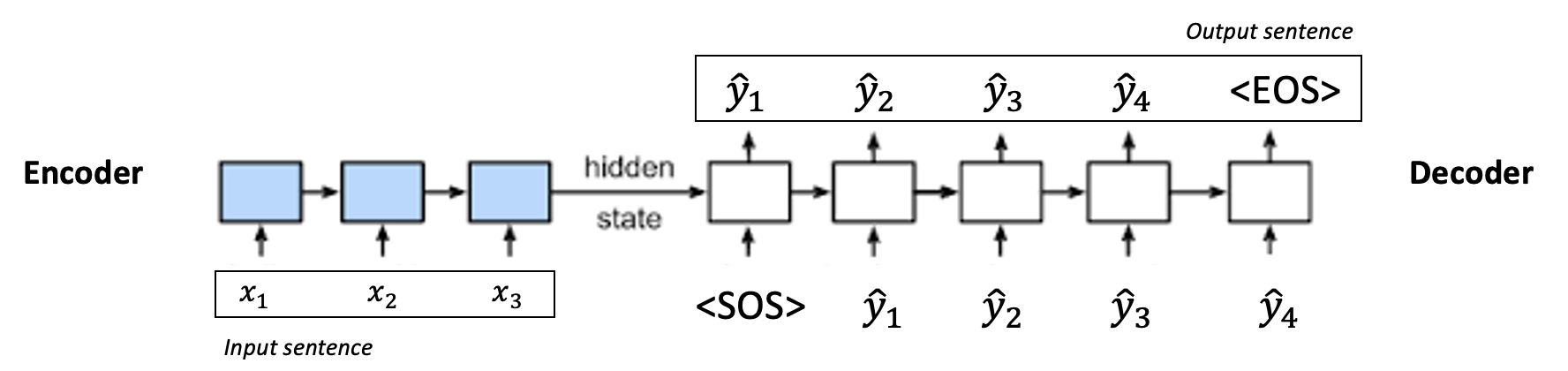
Seq2Seq Model
Sequence-to-sequence model is a common framework for solving sequential problems which has been widely used in NLP tasks.In seq2seq models, the input is a sequence of certain data units and the output is also a sequence of data units. Traditionally, these models are trained using a ground-truth sequence via a mechanism known as teacher forcing, where the teacher is the ground-truth sequence. However, due to some of the drawbacks of this training approach, there has been significant line of research connecting inference of these models with reinforcement learning techniques.
BLEU
BLEU (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
The formulation of BLEU has two components: the modified n-gram precision and the brevity penalty component.

Problems of Standard NMT Model
Mismatch between training objectives: In the training phase of standard NMT model, we minimize the cross-entropy loss between the target sentence and output sentence, which aims at maximizing the likelihood of the model to produce the target sentence conditioned on the input. However, we use BLEU as metric for evaluation. This is because BLEU is non-differentiable, so we cannot build a loss function with it and do minimization. In RL, we could solve this problem by defining a reward function and maximizing expected return based on that reward function.In this case, we don’t need the rewrad function to be differentiable.
Exposure Bias: During the training phase of standard NMT model, we will also use teacher forcing to deal with the large state and action space, and it means that when we are using teacher forcing the input of the decoder will be the ground truth, instead of its own output from previous timestep. However, in the evaluation phase, we won’t have access to the ground truth and all we have is the input sequence. This will make the training and evaluation are done on different probability distribution, and it’s definitely has a negative effect to our model.
REINFORCE in Seq2Seq
REINFORCE is a very classical policy gradient method.

Since REINFORCE is a Monte-Carlo algorithm and the nature of this NMT task, we will only receive the reward and do the update only at the end of each episode, thus the reward we recieve is very sparse. In order to make the reward less sparse, we have to do reward shaping, in which we will define intermediate reward for each intermediate steps within an episode.
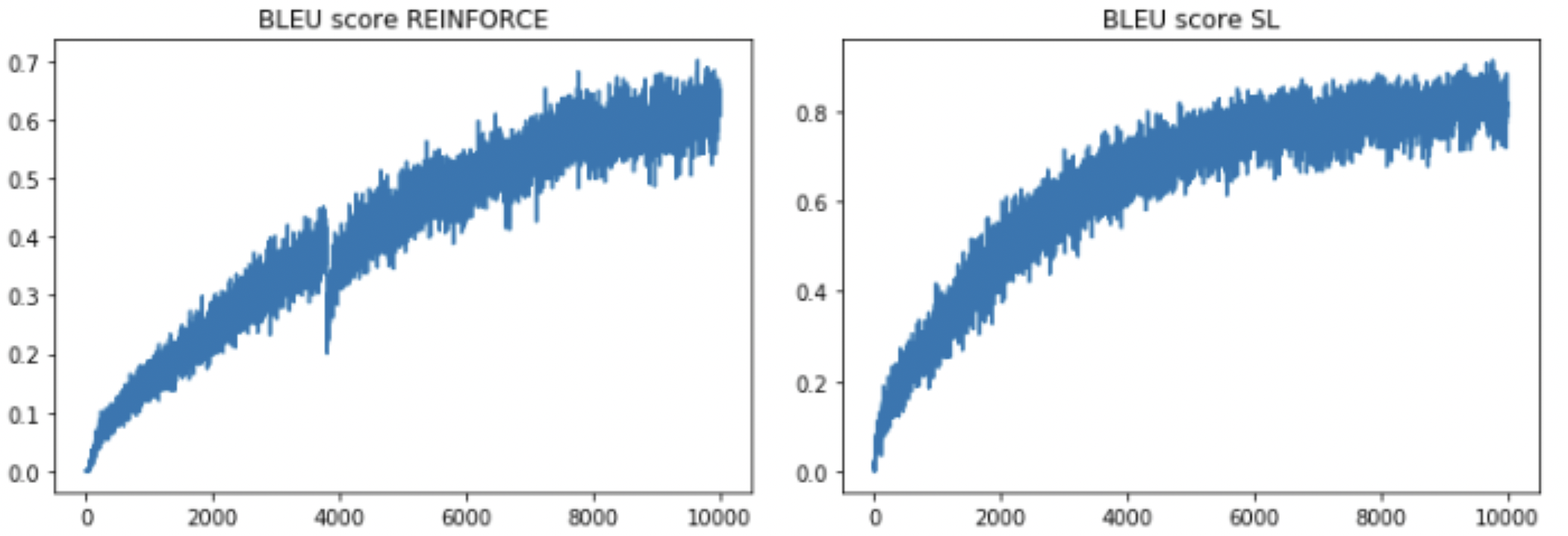
After converged, reinforcement learning model has 10.48 BLEU-3 score on test set, while supervised learning model has 10.23.
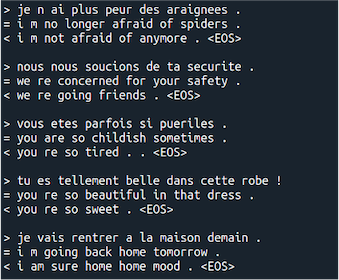
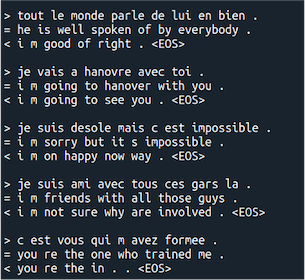
Sample results of both models (left: RL; right: SL) show no obvious qualitative improvement is achieved.
Analysis: We can see that SL model performs slightly better during the training phase, while that is because we are using teacher forcing. We could also see that REINFORCE does have higher variance and need more time to converge during the training. By visualizing the sample results, though we cannot directly compare the performance, it shows that the model is making sense in some ways.
Actor-Critic in seq2seq
Similarly as REINFORCE towards Monte-Carlo, Actor-critic is an algorithm that use temporal difference to update the policy, and there will be a critic network serves as value function, instead of doing reward shaping and calculating cumulative reward as return for each timestep.

Here is the general structure of Actor-Critic model:
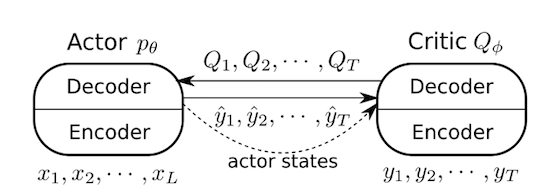
The actor and the critic will both be encoder-decoder based seq2seq model, and the actor network is almost the same as the seq2seq model in REINFORCE. The critic network takes in the ground truth at encoding phase, and the outputs of the actor network at decoding phase (I removed the input summary calculated by attention mechanism, haven’t known of the effect of this change). We hope that the critic network will learn the state value defined as the future expected return for each state, and then the actor will update the policy based on the temporal difference.
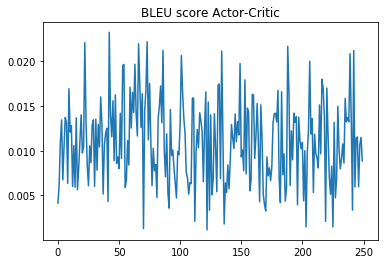
The pretraining goes very well; the actor has been trained to have performance of 0.05 on BLEU-3 score, and the critic could also converge using the fixed actor and make reasonable prediction. However, when it comes to algorithm 1 (the major training part) the model appears to learn nothing and stay at the pretrained performance. I believe that the failure is mostly because of the so many modification I’ve made to the algorithm, especially the bellman update formulation – there must be a reason for them to use it instead of simple prediction for value of next state.
Analysis: Though I didn’t make the Actor-Critic model work in experiment, we can still learn from it. Actor-Critic algorithm aims at using a critic network to optimize the policy and at the same time exploit the environment. In the paper, they construct a powerful model which not only complete the NMT task but also able to deal with spelling correction (this is also a part of the reason that I think I can make it still work even without several components). Through the algorithm, they use Bellman update everywhere and sum over the action space several times per iteration. This is like a trading computation resource for performance (low variance, bias) to me, and I do think there should be a way to trade this computation resource back.
Summary
Through this project, I learnt standard training methods and reinforcement learning implementations on NMT, by reading papers and going through tutorials. After that, I reproduce the REINFORCE and Actor-Critic approach from scratch (REINFORCE works but Actor-Critic doesn’t), and then did analysis and comparison between the two models. A high-level conclusion is that RL has a great potential in NMT field, and it will be great to participate in future investigation in RL in NMT. After this project I will keep doing research with RL in Seq2Seq model, and this project definitely has benefited me a lot.
More Details
The full report is available here, and the codebase is available on my github.